Quantitative Evaluation
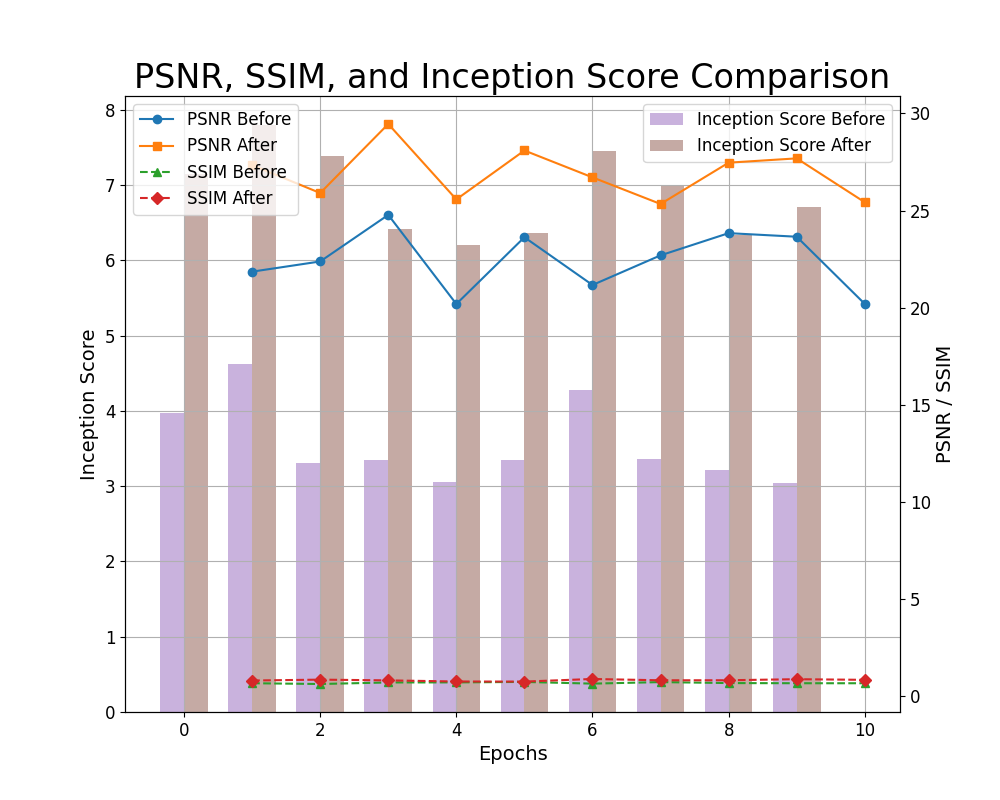
In this graph, we compare PSNR, SSIM, and Inception Score across 10 epochs of training.
The PSNR values after optimization show consistent improvement, peaking at 30 dB, indicating better image quality. The SSIM values rise from 0.6 to 0.9, demonstrating improved structural similarity in the images.
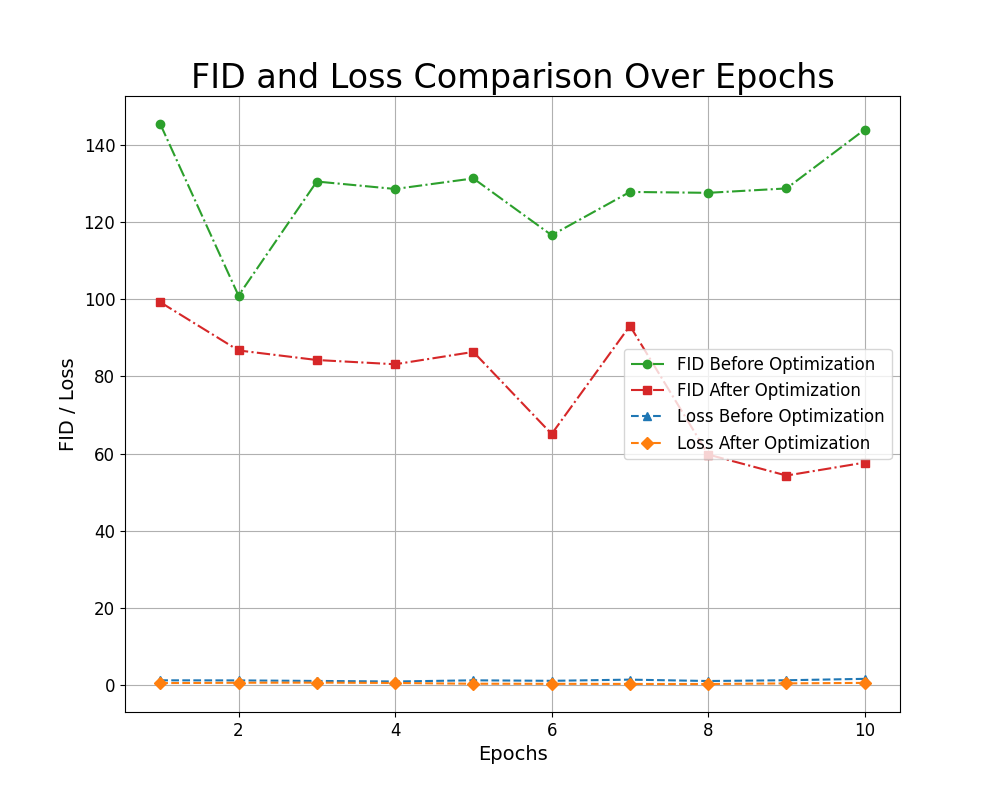
The FID before optimization starts high at 140, showing minimal improvement over epochs. After optimization, it decreases significantly from 120 to 60, indicating better perceptual quality in the generated images.
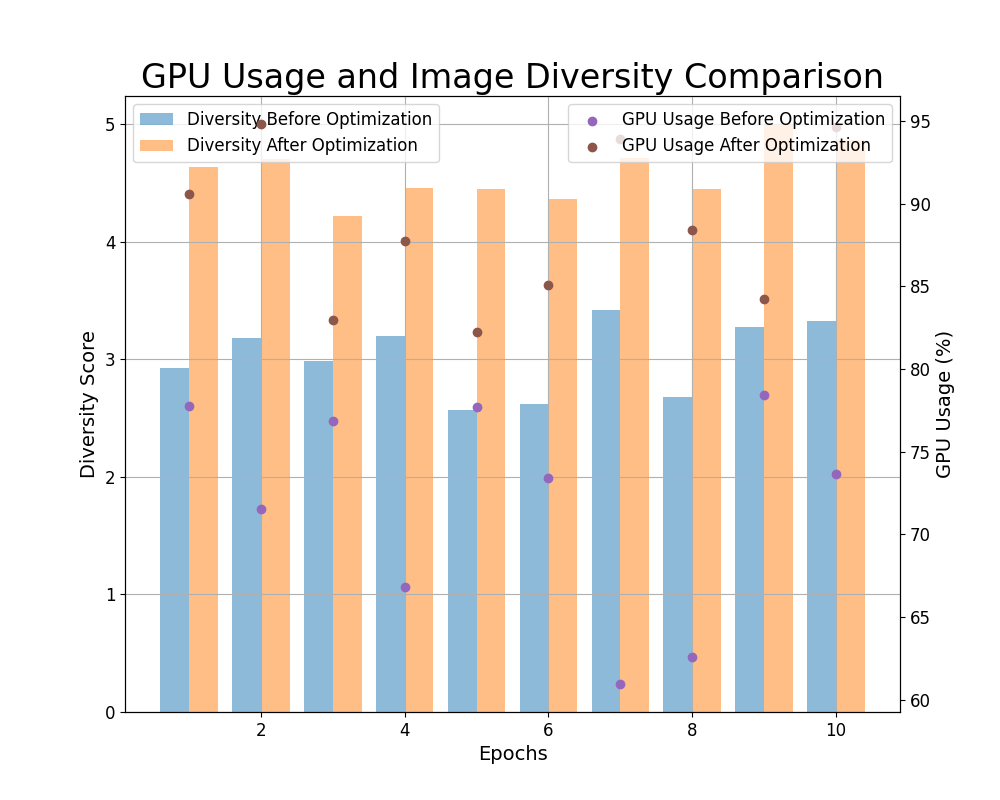
In this figure, we compare GPU usage and image diversity over the 10 epochs.
GPU Usage before optimization hovers around 65-75%, while post-optimization, it increases to 80-95%, reflecting better GPU resource utilization during optimized training.
Image Diversity Score also shows a marked improvement. Pre-optimization scores are between 2.5 and 3.5, while post-optimization scores increase to 4.0-5.0, indicating greater variation and creativity in generated images./